About the Pitfalls of Device Abstractions
When talking about the Internet of Things (IoT), you quickly get into the discussion about device abstraction. As a software engineer, it is natural that you want to represent a physical switch as a boolean value and a sensor measurement as a simple number. It is hard to understand why every hardware manufacturer and every alliance comes up with yet another way to access their devices, when all there is to do is to send a few numbers across. In order to simplify this plethora of options, device abstraction layers were invented.
Actually, there is already a very common way to represent things (aka objects) in software: Object-oriented design! So let us create an abstract model of a television:

As a consequence, a more clever approach is to split devices into their functionalities in order to have reusable (and thus abstracted) parts. A device then becomes an object with a set of functions, often also called capabilities. Steven Posick wrote a very good blogpost about why capabilities-based programming makes a lot of sense for IoT. Let's see how our representation could look like that way:
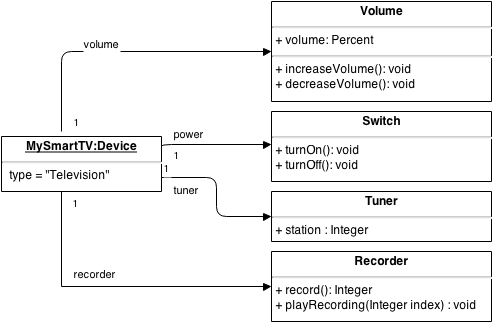
This is already much better as the commonalities are defined on a finer-grained level. Still, another problem creeps in from the opposite direction as well: The primitive types, which build the "atoms" on which the device abstraction is based. Are the usual primitive types a good choice? A magnetic sensor status can be represented as true/false - or rather false/true? A TV station can be a simple integer. But which integer is then CNN and which ESPN? These questions suggest that there is too much ambiguity in such a model and hence the use of enumerations seemy to be a logical choice. On a closer look, we are now back at the same problem we had before: While modelling the functionality, such as the channel, as a primitive type (here integer), this is fine for more or less all devices. By introducing a channel list as an enumeration, this is all of a sudden very device-specific and hardly reusable for other TVs. This is the same effect for all other constraints on values: What is the frequency range of my tuner? Which step size does my thermostat support and what is its maximum value? All such constraints are very device-specific and hence should be treated as (specific) meta-data in the model.
A similar situation applies to units: Sensors provide values in a certain unit and this is often directly built into the hardware. Depending on their manufacturer and intended use case, a temperature sensor might deliver values as Kelvin, degrees Celsius or degrees Fahrenheit. It is therefore not a good idea to define the unit of a value on the abstraction layer - this would again reduce the possibility to find a generic "TemperatureSensor" abstraction or rather would introduce three different versions of it. The better choice is therefore to treat the unit as meta-data.
Contemplating about dimmers brings up yet another angle: Is it really the dimmer that the user or application is interested in? No, the dimmer is only a mean to change the light that is plugged into it. Likewise a magnetic contact is not in the focus itself - instead, it is the door where it is attached to. The temperature of a sensor is not interesting at all, but the temperature of the room it is in is. Ideally, we would like to work with concepts like "door", "room", "pet" in the application layer, not necessarily with the devices themselves. Such a collection of concepts is usually called an ontology. In an ontology, the relations between the concepts are described and lead to semantical meaning, through which implicit knowledge can be deduced.
For a device abstraction layer, such an ontology brings insurmountable obstacles: A device manufacturer simply cannot know about the concrete usage of the device and thus cannot provide the semantical classification. It is merely the installer or user who has the required knowledge. If he e.g. connects his fridge to a smart plug in order to measure its energy consumption, he clearly would not want it to be turned off by an "all-off" scenario. He therefore needs to teach the system about this, either explicitly or implicitly through his behavior. The latter means that the system can only learn through trial & error, which sounds nice when being called "self-learning" in marketing material, but which can lead to quite some frustration for the users - there is a great post on this by Johannes Ernst about the Nest thermostat. I fully agree that this is an easy hard problem.
Separating functions from the physical device also means that you might have to deal with multiple locations - if you want to "turn off all lights in your kitchen" then this should include the light that is controlled through the actuator which is located in your electrical cabinet. If this actuator has multiple channels, there is one physical location (the cabinet), but multiple functional locations. This again is an information that needs to be taught to the system. For the daily usage, the device and its location are hardly relevant, but the locations of the functions are.

Actually, there is already a very common way to represent things (aka objects) in software: Object-oriented design! So let us create an abstract model of a television:
Has OOD failed, again?
The obvious problem here is that this is indeed "a" television. But this class is not usable for all TV sets that are out there - old CRTs have hardly any functionality and modern smart TVs include a triple-tuner, hard-disc recording etc. So how should this single representation suit them all? Well, you could simply add all potential functionality of a TV to this class and declare most of them optional. But this effectively means that your application has to deal with NotImplementedExceptions for 90% of the called methods in the end - the application degenerates into an exception handling facility... Somehow this reminds me of the fact that I was never convinced that OOD is the right thing for todays problems.As a consequence, a more clever approach is to split devices into their functionalities in order to have reusable (and thus abstracted) parts. A device then becomes an object with a set of functions, often also called capabilities. Steven Posick wrote a very good blogpost about why capabilities-based programming makes a lot of sense for IoT. Let's see how our representation could look like that way:
This is already much better as the commonalities are defined on a finer-grained level. Still, another problem creeps in from the opposite direction as well: The primitive types, which build the "atoms" on which the device abstraction is based. Are the usual primitive types a good choice? A magnetic sensor status can be represented as true/false - or rather false/true? A TV station can be a simple integer. But which integer is then CNN and which ESPN? These questions suggest that there is too much ambiguity in such a model and hence the use of enumerations seemy to be a logical choice. On a closer look, we are now back at the same problem we had before: While modelling the functionality, such as the channel, as a primitive type (here integer), this is fine for more or less all devices. By introducing a channel list as an enumeration, this is all of a sudden very device-specific and hardly reusable for other TVs. This is the same effect for all other constraints on values: What is the frequency range of my tuner? Which step size does my thermostat support and what is its maximum value? All such constraints are very device-specific and hence should be treated as (specific) meta-data in the model.
A similar situation applies to units: Sensors provide values in a certain unit and this is often directly built into the hardware. Depending on their manufacturer and intended use case, a temperature sensor might deliver values as Kelvin, degrees Celsius or degrees Fahrenheit. It is therefore not a good idea to define the unit of a value on the abstraction layer - this would again reduce the possibility to find a generic "TemperatureSensor" abstraction or rather would introduce three different versions of it. The better choice is therefore to treat the unit as meta-data.
Configuration Hell
Very often, a huge part of a device' functionality is exclusively used for its configuration. The configuration options of a device are highly hardware-specific and thus hard to abstract. Treating configuration functionality separate from "operational" functionality is therefore useful. A good example is a "simple" dimmer: Its operational functionality is fairly easy: It has a state between 0 and 100 and this can be set through an operation. But in order to configure this behavior, there is a multitude of different options: Individual dimming curves can be defined depending on the type of bulb. How quickly should the new value be reached, i.e. is there a smooth transition? Is it at all ok to dim the connected device or must it only be switched on and off? Should it turn to 100% when being switched on or shall it remember the state before it had been turned off? Some dimmers actually come with 20 and more options for their configuration - a really strong reason for not trying to generalize this. |
| Dimmers from different manufacturers |
Contemplating about dimmers brings up yet another angle: Is it really the dimmer that the user or application is interested in? No, the dimmer is only a mean to change the light that is plugged into it. Likewise a magnetic contact is not in the focus itself - instead, it is the door where it is attached to. The temperature of a sensor is not interesting at all, but the temperature of the room it is in is. Ideally, we would like to work with concepts like "door", "room", "pet" in the application layer, not necessarily with the devices themselves. Such a collection of concepts is usually called an ontology. In an ontology, the relations between the concepts are described and lead to semantical meaning, through which implicit knowledge can be deduced.
For a device abstraction layer, such an ontology brings insurmountable obstacles: A device manufacturer simply cannot know about the concrete usage of the device and thus cannot provide the semantical classification. It is merely the installer or user who has the required knowledge. If he e.g. connects his fridge to a smart plug in order to measure its energy consumption, he clearly would not want it to be turned off by an "all-off" scenario. He therefore needs to teach the system about this, either explicitly or implicitly through his behavior. The latter means that the system can only learn through trial & error, which sounds nice when being called "self-learning" in marketing material, but which can lead to quite some frustration for the users - there is a great post on this by Johannes Ernst about the Nest thermostat. I fully agree that this is an easy hard problem.
Separating functions from the physical device also means that you might have to deal with multiple locations - if you want to "turn off all lights in your kitchen" then this should include the light that is controlled through the actuator which is located in your electrical cabinet. If this actuator has multiple channels, there is one physical location (the cabinet), but multiple functional locations. This again is an information that needs to be taught to the system. For the daily usage, the device and its location are hardly relevant, but the locations of the functions are.
Static Descriptions vs. Dynamic Behavior
Assuming you successfully managed to classify all your devices nicely and have a generalized description of them, a new problem comes up once you start using your system: The dynamic runtime behavior. A static description can quickly render useless when devices are operated:- Changing the mode of your heating system between "manual" and "automatic" will radically change the set of available options for the current mode. So how could one describe availability of functions and options that depend on certain values of other functions?
- Sensor values can be pulled or pushed - how often does this happen? Is pushing done at a fixed rate or only upon a change in the value (and with which threshold)?
- When sending a command to a device, is this directly transferred or will it take a while as the device might be in a (battery-optimized) sleep mode? How long does the operation take to be fully completed?
- What error situations can occur and how can this be determined? Are there recovery options?
- Are state changes described through a state machine? Is there maybe even the need for transaction support?
All of this would be nice to know for an application - but at the same time, this all is very device specific and cannot be abstracted away. In consequence, applications will either be simplified, i.e. they cannot cover every single detail and situation in an optimal manner or they are device specific. Usually one will end up somewhere in the middle. In practice, almost all so-called device abstraction layers are in reality device access abstraction layers, i.e. they provide the same API for accessing different kinds of devices, but they do not abstract their functionality. Even describing the pure hardware-related characteristics in a good - and common - way is already very hard. The European Commission is currently running a study about ontologies for smart appliances with the goal to distill the commonalities into a single ontology - the result will be surely interesting.
So how does Eclipse SmartHome actually deal with all those complex problems?
As the initial code base came from the openHAB project, there is a strong focus on a high functional abstraction level. In openHAB, one of the main concept is that of an item, where an item represents a specific function. Items are on the "virtual" or "modelled" layer of the system architecture and thus they can exist independently of any real hardware. An important design principle is that it should be possible to replace hardware without having to do any changes to the items and thus the application level, which is the user interface and the automation rules. The item types are very limited and partially rather abstract/primitive like "Number" or "String", in some cases more concrete and specific for the smart home domain like "Rollershutter" or "Color" - the set of item types is kept small and new additions are thoroughly discussed. In general, items are meant to be useful on the application level, but the true semantics are usually brought into the system by the user as he designs the UI and the automation rules in a way that they support his use cases.
openHAB 1.x actually completely does without the notion of a device - instead, items are directly bound to a certain functionality of a device through an appropriate configuration. This was possible for openHAB as it concentrated on the operational side and did not provide any (runtime) functionality for system setup and configuration.
In Eclipse SmartHome, configuration facilities are a major focus for new contributions. For this reason, the thing concept has been introduced as a complement to the item concept. It does not only allow describing the functionality and structure of things in a common way, but also provides relevant information to build user interfaces on top, including internationalization support. Once the new Eclipse Vorto project is in place, its repository can be a good source for adding additional device support into bindings by generating the appropriate thing type descriptors.
The static way of describing things through XML is just one (default) possibility of providing thing types in Eclipse SmartHome though - the framework allows dynamic providers at the same time, so that the structure of things can also be provided dynamically at runtime. The name "thing" was chosen over "device" in order to allow "virtual" things, such as web services or an arbitrary source of information, as well. It is important to note that so far there is no thing taxonomy (i.e. a classification system) in Eclipse SmartHome yet. Different solutions built on Eclipse SmartHome might use different taxonomies - for this reason, this has not been addressed so far.
Tagging to the Rescue
A more powerful concept than a simple taxonomy is currently in implementation: Tagging support. The basic idea is to provide a very simple mean to add semantical information to items, so that they can be easily consumed by applications - tags could be e.g. something like "light" or "alarm", i.e. their definition should be use case driven and not device driven. Thing type descriptions can "suggest" default tags for items that are linked to their channel, but the user should have the chance to change the tags on an item in order to provide semantical information that reflects his personal usage of things. Although it is a simple concept, I am convinced that it can support many nice use cases without adding too much burden on developers - when targeting a developer community, the "power by simplicity" principle is very important to adopt.
I'd love to hear about your experiences and ideas on this topic - feel free to join the discussion!
openHAB and Eclipse SmartHome News Flash
JavaOne and the Valley
Having spent a few days in the Silicon Valley, I feel it is time to share some experiences. The main reason for the my trip was the talk about Smart Homes for the Masses at JavaOne in San Francisco. This was well attended and we had brought a lot of toys with us to do a live demo of Eclipse SmartHome and QIVICON. There were other good talks about home gateways like the one from ProSyt about OSGi on gateways or from Eurotech about the Eclipse Kura project.Thanks to the Eclipse Foundation, we also had two slots at the Eclipse booth in the exhibition hall to demonstrate Eclipse SmartHome and talk to people about it. Ian Skerrett even did an impromptu video recording of our demo setup.
Besides the very professionally organized conference by Oracle, it is always remarkable, how the "normal" life of IT geeks look like in the valley. I had the chance to present the Eclipse SmartHome based openHAB project at a local MeetUp in Oakland, hosted by ACE Monster Toys. Behind the rather uninviting entrance in an industrial area, there are great tools for the startups of tomorrow: huge CNC-machines, lots of sewing machines, powerful laser cutters etc. Entrepreneurs from all over the valley meet here to discuss latest technologies - such as openHAB in this case! On this occasion, I was given one of the new GE LED light bulbs, which are at less than $15 incredibly cheap in comparison to any other radio controlled light bulb on the market. And what is cool about it: It can be linked to the Philips Hue bridge and is now fully supported by the Eclipse SmartHome Hue binding!
At this MeetUp, I also had the pleasure to meet the creator of the STACK Box, a recently funded Kickstarter project. I really like the concepts this project is following as they are very much in-line with the idea of openHAB: Having an open and extensible software stack for a home gateway that serves as an integration point while protecting the users privacy. Did I actually already mention that I consider myself a home gateway junkie? Over the years I have collected an impressive compilation - and yet I am still missing popular gateways like the SmartThings hub, the Revolv hub, the Ninja Sphere or the Wink hub...
On October 3rd, I was invited to the TWiT studios in Petaluma for an interview - they have a special FLOSS channel and usually broadcast live - as I couldn't arrange the usual time, they made an exception for me and did a pre-recording. Their studio is amazing and they have a very professional crew - well, see the results of the show yourself!
EclipseCon Europe is coming!
Shortly after JavaOne, we had reached an important milestone for Eclipse SmartHome - the very initial release has been published - Eclipse SmartHome 0.7.0! A main feature of it over the initial code base from openHAB is the support of discovery mechanisms for bindings. The first developers are now actively trying this out and thus I am thrilled to already see support for Philips Hue, Yahoo Weather, Sonos, LIFX, Belkin Wemo, MAX!Cube, KNX, IRTrans and others being developed! I will soon do a blog post that shows this in action and should give you a good idea of how solutions that are built on Eclipse SmartHome can look like - so stay tuned!
If you are close to Ludwigsburg end of October, a good chance to see the first results is at my talk at EclipseCon Europe, which I am doing together with my colleague Jochen Hiller from Deutsche Telekom. You can also learn how to implement a binding yourself in 15 minutes or get your hands dirty at the IoT playground. If you are interested in the Eclipse IoT space in general and would like to meet the different people involved in it, the Unconference that is held on Monday, Oct 27th, is a good opportunity to do so - hoping to see you there!
If you are close to Ludwigsburg end of October, a good chance to see the first results is at my talk at EclipseCon Europe, which I am doing together with my colleague Jochen Hiller from Deutsche Telekom. You can also learn how to implement a binding yourself in 15 minutes or get your hands dirty at the IoT playground. If you are interested in the Eclipse IoT space in general and would like to meet the different people involved in it, the Unconference that is held on Monday, Oct 27th, is a good opportunity to do so - hoping to see you there!
"Forget Me Not" with openHAB and EnOcean
You might have heard about the Forget Me Not Design Challenge that has been organised by element14. There were brilliant submissions and the participants for the challenge have been chosen end of July. As openHAB and EclipseIoT are both sponsors, I am personally very much looking forward to the results of this challenge.
As all participants received hardware from EnOcean (who is another sponsor), a major use case is accessing EnOcean devices with openHAB. While there is an EnOcean binding for openHAB since quite a while already, there are a few glitches that you could come across when using it with a Raspberry Pi or even an EnOcean Pi (as the participants do), so I will try to provide some helpful information here.
First of all, setting up the Raspberry Pi and installing openHAB is quite straight forward - Inderpreet has compiled a very good tutorial for this - thanks!
If you then add the EnOcean binding in your addons folder, configure the serial port (which is /dev/ttyAMA0 for any board attached to the GPIO pins (as is the EnOcean Pi module), add some binding configuration to an item and start up openHAB you will see - nothing.
Now, there are three things to do to make it work:
As all participants received hardware from EnOcean (who is another sponsor), a major use case is accessing EnOcean devices with openHAB. While there is an EnOcean binding for openHAB since quite a while already, there are a few glitches that you could come across when using it with a Raspberry Pi or even an EnOcean Pi (as the participants do), so I will try to provide some helpful information here.
First of all, setting up the Raspberry Pi and installing openHAB is quite straight forward - Inderpreet has compiled a very good tutorial for this - thanks!
If you then add the EnOcean binding in your addons folder, configure the serial port (which is /dev/ttyAMA0 for any board attached to the GPIO pins (as is the EnOcean Pi module), add some binding configuration to an item and start up openHAB you will see - nothing.
 |
| The EnOcean Pi module fits nicely into the openHAB Raspberry Pi case |
- The first step is to disable the Raspberry Pi's serial console.
- Next, you need to make sure that the user under which you run openHAB belongs to the group "dialout", otherwise you won't have access to the serial port.
- In theory, the EnOcean Pi module can now be accessed. Unfortunately, the RXTX library that is used by openHAB for connecting to serial ports does not consider /dev/ttyAMA0 to be a standard port and thus simply does not recognise it. You therefore have to explicitly declare it through the JVM parameter "-Dgnu.io.rxtx.SerialPorts=/dev/ttyAMA0" in the start(_debug).sh launch script.
Starting openHAB after making these changes leads to the desired result:
20:13:44.588 INFO o.o.b.e.i.bus.EnoceanBinding[:290] - Connecting to Enocean [serialPort='/dev/ttyAMA0' ].
20:13:45.951 INFO org.enocean.java.ESP3Host[:66] - starting receiveRadio..
A last remark: EnOcean is a pretty cool technology for sensors and this is what it is mainly used for. Nonetheless there are also actuators available and if you try one of these with openHAB you will notice that the current binding does not bring support for EnOcean actuators. There is hence no official solution for this problem. Still, there is somebody working on another EnOcean binding for openHAB, which also has actuators in the scope. As far as I know, this is still in an early stage, but if you really want to go for actuators, you might want to try it out.
Open Source as the Best Alternative
There we have it. Already one day before Google I/O starts, the Google approach to a smart home ecosystem has been published. So just a few days after Apple's announcement of HomeKit, we developers are confronted with the choice of two completely new approaches: The one from Apple with a focus on privacy, but limited to the upscale Apple device universe. The other from Google Nest, where everything is cloud based and where privacy is at risk. Although Nest currently tries hard to convince people of the opposite, which is especially necessary after acquiring Dropcam - but the evidence is too crystal clear that mothership Google will offer sweet candy to Nest users, so that they sooner or later share their data and eventually get ads on their thermostats and other devices.
So is this the destiny of smart homes? Being either fully equipped with Apple hardware or permanently connected to the Google cloud sharing every single detail? Well, luckily there is a third option - and one that has already proven to be a success story in other domains already: Open source! There are clear benefits of an open source solution:
So is this the destiny of smart homes? Being either fully equipped with Apple hardware or permanently connected to the Google cloud sharing every single detail? Well, luckily there is a third option - and one that has already proven to be a success story in other domains already: Open source! There are clear benefits of an open source solution:
- There is no single company having full control and power
- It is future proof as it continues to exist even if a company disappears or changes direction
- It drives innovation through community engagement
- It is flexible as anybody can extend it and adapt it to their needs
The best example for the innovation that is happening in the IoT and smart home space is what people do with the Raspberry Pi - it is incredible what this small little device is used for.
I am therefore very thrilled that openHAB is involved in organizing the "Forget Me Not" Design Challenge together with element14 and the Eclipse Foundation. Participants in this challenge will receive hardware including a Raspberry Pi, EnOcean sensors and a Tektronic oscilloscope. With this equipment, they are encouraged to build an IoT solution based on the Eclipse SmartHome framework. We will provide developer builds of openHAB 2.0 to them as a ready to go solution that is able to talk to EnOcean devices. As a preparation for this, we will present the possibilities of Eclipse SmartHome and openHAB during a webinar on July 8 - so do not miss to register for it and help building the smart home future on open source technologies!
openHAB 2.0 and Eclipse SmartHome
As I am regularly asked how the projects openHAB and Eclipse SmartHome relate to each other, so I would like to take a chance to provide background information on this topic.
Since its inception in 2010, openHAB's popularity is constantly growing and our community is spread all over the world. Besides being used by end users and developers, openHAB is more and more adopted in academia, research and industry projects. Seeing the project maturing this way, two decisions were taken in 2013:
 We (that is myself, Thomas Eichstädt-Engelen and Victor Belov) founded the openHAB UG (haftungsbeschränkt), a small limited company with the sole purpose to run, back and support the openHAB project. The company has no commercial interest and we are fully committed to keep openHAB as a leading open-source smart home solution. Having this company as a legal entity behind openHAB now allows becoming a member of alliances and other activities. The company therefore has official developer accounts at Apple's Appstore and Google's PlayStore in order to be able to distribute the iOS and Android apps for openHAB. Furthermore, the openHAB UG is a member of
We (that is myself, Thomas Eichstädt-Engelen and Victor Belov) founded the openHAB UG (haftungsbeschränkt), a small limited company with the sole purpose to run, back and support the openHAB project. The company has no commercial interest and we are fully committed to keep openHAB as a leading open-source smart home solution. Having this company as a legal entity behind openHAB now allows becoming a member of alliances and other activities. The company therefore has official developer accounts at Apple's Appstore and Google's PlayStore in order to be able to distribute the iOS and Android apps for openHAB. Furthermore, the openHAB UG is a member of
What exactly does this mean for the architecture of openHAB 2.x?
Since its inception in 2010, openHAB's popularity is constantly growing and our community is spread all over the world. Besides being used by end users and developers, openHAB is more and more adopted in academia, research and industry projects. Seeing the project maturing this way, two decisions were taken in 2013:
openHAB UG (haftungsbeschränkt) as a legal entity for openHAB
- the EnOcean Alliance - Since we provide a solution that works well with EnOcean hardware, this was a natural step.
- the AllSeen Alliance - Their AllJoyn open-source technology can be a nice complement to openHAB as it unifies higher-level IP-based communication between end devices and could open the door for openHAB to many new devices though a single new AllJoyn-binding.
- the Eclipse Foundation - openHAB has always been based on many Eclipse projects, such as Equinox, Jetty and Xtext. But the main reason to join the Eclipse Foundation was this:
Kicking off the Eclipse SmartHome project

To enable others to use code from openHAB in their own solutions and products, we wanted to put the code base on a solid and trustworthy foundation. Th legal aspects of many open-source projects are often pretty fuzzy, even if they have a permissive license. But for companies using such project in their own products, there is always the risk that the copyright of the code is not clear and that the code might be contaminated by patents. To reduce such risks, it is very beneficial to have a rigid intellectual property management and clear contribution processes - this is one of the things that a foundation such as Eclipse provides. We therefore decided to contribute the core framework of openHAB to the Eclipse Foundation, which became the new Eclipse SmartHome project.
So has openHAB now been replaced by Eclipse SmartHome? Not at all - it is important to note that Eclipse SmartHome is only a framework (comprised of a set of OSGi bundles) to build smart home solutions on top. Although there are binary runtime downloads available for Eclipse SmartHome, these should only be seen as a demonstration of what can be done with Eclipse SmartHome - they are not meant as an end customer solution. The main deliverable of the project is a repository of the different bits and pieces to build solutions on top. There are already industry players actively contributing to the project and it can therefore be expected that commercial customer solutions become available later this year, which are based on the Eclipse SmartHome framework. One solution that can be counted on is openHAB - the new development branch of version 2.x is now based on Eclipse SmartHome.openHAB 1.x versus openHAB 2.x
This leads us to the next questions: Is openHAB 1.x now replaced by openHAB 2.x? When will this be available? And what are the differences and (in)compatibilities?
Well, openHAB 1.x is currently still the main development stream and very active - we have just released version 1.5 and hit a new record in the number of available add-ons; we are close to 100 now!
We will continue the openHAB 1.x branch - the focus being on the bindings and other add-ons. For the core runtime and the designer, only critical bugs will be fixed. So if you are a user rather than a developer, this is the version you should be after.
openHAB 2 has a different focus: User comfort. While in openHAB 1.x you need to configure everything in text files and figure out the right syntax and possibilities of a certain binding in the wiki, openHAB 2 allows bindings and other add-ons to self-describe their configuration, so that it is possible to offer user interfaces for system setup and configuration. Additionally, auto-discovery (e.g. through UPnP, AllJoyn, etc.) is offered, so that new devices can be added by a simple click of a button. Chris Jackson has already built a lot of convenient UIs for openHAB 1.x, which are available as HABmin - this even includes a graphical rule editor based on blockly. We are striving for refactoring and integrating these things as a core part of openHAB 2.x and thus not requiring the users to use configuration files at all (but of course leaving it as an option).
 A second major design goal of openHAB 2.x is the optimization for embedded platforms. Although openHAB 1.x works on a Raspberry Pi, it sometimes feels a bit sluggish at startup or with huge installations - this is due to the fact that openHAB had never been specifically optimized for embedded systems and thus uses libraries such as Xtext, which are not meant to be used in constrained environments. In consequence, we will try to provide a minimal openHAB runtime that will work with alternatives or strategies such as pre-compilation etc.
A second major design goal of openHAB 2.x is the optimization for embedded platforms. Although openHAB 1.x works on a Raspberry Pi, it sometimes feels a bit sluggish at startup or with huge installations - this is due to the fact that openHAB had never been specifically optimized for embedded systems and thus uses libraries such as Xtext, which are not meant to be used in constrained environments. In consequence, we will try to provide a minimal openHAB runtime that will work with alternatives or strategies such as pre-compilation etc.
openHAB 2 has a different focus: User comfort. While in openHAB 1.x you need to configure everything in text files and figure out the right syntax and possibilities of a certain binding in the wiki, openHAB 2 allows bindings and other add-ons to self-describe their configuration, so that it is possible to offer user interfaces for system setup and configuration. Additionally, auto-discovery (e.g. through UPnP, AllJoyn, etc.) is offered, so that new devices can be added by a simple click of a button. Chris Jackson has already built a lot of convenient UIs for openHAB 1.x, which are available as HABmin - this even includes a graphical rule editor based on blockly. We are striving for refactoring and integrating these things as a core part of openHAB 2.x and thus not requiring the users to use configuration files at all (but of course leaving it as an option).
What exactly does this mean for the architecture of openHAB 2.x?
- The core runtime and its APIs will change fundamentally. We deliberately use the chance to do backward compatibility breaking changes to it in favor of the above mentioned goals.
- In consequence, the source repository of openHAB 2 will start with no bindings at all and we encourage the developers in our community to migrate their existing 1.x bindings to the 2.x concepts, once these are fully in place.
- For the time being, there is a "1.x compatibility bundle" that allows to use openHAB 1.x add-ons with the openHAB 2 runtime - this will not run for all of them out of the box, but for the majority of them.
The good news is that we have now the first developer builds available of openHAB 2! If you try this out (note that it is still under development and not meant for users, but rather developers), you will immediately see a couple of major changes:
- The central configuration file "openhab.cfg" is gone. Instead, you can now have a separate file for every add-on. This clearly improves the overview over your configuration parameters as your configuration file won't be cluttered with information about add-ons that you are not using.
- The whole directory structure has been overhauled - there are now three main folders: "runtime" containing the binaries and other content that is needed to run the system. "conf", which holds all your personal configurations and customizations (such as e.g. custom icons). "userdata", which is the only directory that the system actively writes to (log files, databases, etc.). This new structure makes system upgrades much easier and also facilitates the installation on embedded systems where one does not want to use flash memory for continuously writing logfiles etc.
To summarize: openHAB 2 is still in an early phase, but having binary builds with a 1.x compatibility layer available is a significant step forward. You can expect very active development on it in the next weeks and in a few months from now, it should be a worthy replacement for the 1.x runtime.
Shaping the Smart Home market
Moving the core framework to the Eclipse SmartHome project might at first sight seem like adding unnecessary complexity to openHAB. But I sincerely believe that it was the right step for the smart home market in general: The Eclipse Foundation serves as a trustworthy institution that fosters industry collaboration. And collaboration is highly needed - now that Apple has entered the market with introducing HomeKit. Everybody expects Google to be working on something similar after having shown interest in smart homes already in 2011 through the now vanished Android@home and more recently through the acquisition of Nest. So will we see after the smartphone wars now the smart home wars? Will we have to choose all our home appliances in future depending on whether we run our house on iOS or Android? This sounds like the ultimate vendor lock-in, something that I am trying to fight since the beginning of openHAB. We can only escape this future, if the rest of the industry joins forces - the time for proprietary silo solution is up. In my opinion this collaboration can only work through open source - everything else would only end up in competing consortiums that would further drive the market fragmentation. This is why Eclipse SmartHome should be seen as an invitation to the industry to collaborate - it is not so much about using the code that is out there right now, but much more about talking to each other, publicly sharing ideas, and shaping the future together for the better.